The RL4RLA Pipeline
RL4RLA frames algorithm discovery as building symbolic programs from linear-algebra primitives. Four components work together to make discovery tractable.
Symbolic Algorithm Representation
Each candidate algorithm is an explicit symbolic program $\mathcal{A} = (\mathcal{P}_{\text{setup}}, \mathcal{P}_{\text{iteration}})$ built from typed linear-algebra primitives (SKETCH, HHQR, MATVEC, INV, …). Programs are directly executable and human-inspectable.
Curriculum-Guided Discovery
A sequence of staged refinements progressively increases problem difficulty. Each stage introduces exactly one failure mode (ill-conditioning, non-square, high-leverage) resolved by one new algorithmic component. Deep search becomes a chain of shallow problems.
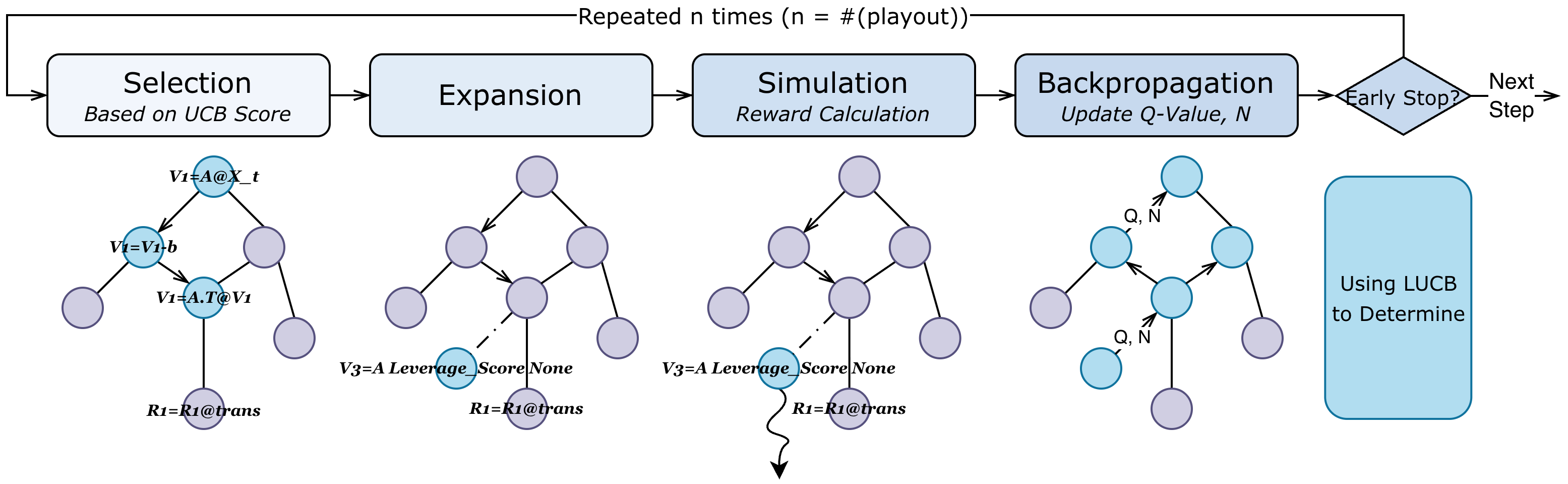
Monte Carlo Graph Search
MCGS operates on a DAG rather than a tree, merging equivalent partial algorithms reached via different action orderings. This reduces growth from $O(b^d)$ tree nodes to $O(|\mathcal{S}|)$ unique states, achieving 2–3× search cost reduction.